원격 텔레메트리 시스템
Ceily/Wally 기기의 모터 상태·위치·토크를 MQTT→AWS IoT→InfluxDB→Grafana로 실시간 수집·시각화하는 모니터링 시스템
배경
- 시스템: ESP32-S3 기반 로봇 기기 (Ceily 천장형, Wally 벽면형)
- 범위: 펌웨어 데이터 수집 → 클라우드 적재 → 시계열 저장 → 실시간 대시보드까지 전 구간
- 단독 수행: 설계부터 구현까지 혼자 진행
핵심 문제
고객 현장에 설치된 기기를 원격으로 볼 수 없었다:
- 고객이 이상을 알려도 원격으로 진단할 방법이 없었다
- 설치 지원 때마다 현장에 직접 가야 했다
- 토크 이상(예: 가구 마찰)은 모터가 손상될 때까지 발견되지 않았다
목표: 기기 데이터를 실시간으로 올려서, 엔지니어가 원격으로 모니터링·진단·설치 지원을 할 수 있게 한다.
핵심 아이디어
텔레메트리를 하나의 스트림이 아니라 샘플링 주기와 보존 기간이 다른 여러 MQTT 토픽으로 나눈다. 모션 데이터는 빠르게 샘플링(0.5초)하되 짧게 보관(7일)하고, 시스템 상태는 느리게 샘플링(30초)하되 오래 보관(1년)한다. 기기에서 샘플을 배치로 묶어 보내 MQTT 오버헤드를 줄인다.
접근 방식
1) 아키텍처
ESP32-S3 (TLS 8883)
│
▼
AWS IoT Core ──── IoT Rule
│
▼
Lambda (influxdb-writer)
│
▼
InfluxDB (Docker, EC2)
│
▼
Grafana Dashboard기기는 TLS 상호 인증으로 MQTT 메시지를 발행한다. AWS IoT Rule이 메시지를 Lambda로 넘기고, Lambda가 JSON을 InfluxDB Line Protocol로 변환해 해당 버킷에 기록한다.
2) 토픽 설계
| 토픽 | 샘플링 | 배치 | 보존 | 데이터 |
|---|---|---|---|---|
devices/{id}/motion | 0.5초 | 10개 / 5초 | 7일 | 위치, 속도, 토크, 모델 파라미터 |
devices/{id}/status | 5초 | 1개 | 30일 | 힙, CPU 온도, 서보 상태, ToF 센서 |
devices/{id}/system | 30초 | 1개 | 1년 | 펌웨어 버전, 업타임, 부팅 횟수 |
devices/{id}/events | 발생 시 | 1개 | 90일 | 상태 변경, 에러, 알림 |
왜 토픽을 나누는가? 데이터마다 쓰기 빈도, 쿼리 패턴, 저장 비용이 다르다. InfluxDB 보존 정책은 버킷 단위로만 걸 수 있어서, 토픽을 나누면 버킷도 자연스럽게 나뉜다.
3) 기기 데이터 수집
모션 텔레메트리는 0.5초마다 샘플링하고, 10개씩 묶어서 한 번에 발행한다:
typedef struct {
uint64_t timestamp_ms;
uint8_t state; // 모션 상태 enum
int16_t position_mm; // 위치 (밀리미터)
uint8_t position_pct; // 0-100%
int16_t velocity_x10; // 속도 × 10 (고정소수점)
int16_t torque_mnm; // 토크 (밀리-Nm)
int16_t remain_distance; // 남은 거리
int16_t command_vel; // 현재 명령 속도
uint8_t speed_control; // 속도 제어 상태
// 토크 모델 파라미터
uint8_t torque_index;
float theta[4]; // 모델 계수
float p[4]; // 추정기 공분산
int16_t predicted_total; // 예측 토크 (mNm)
int16_t threshold; // 적용된 민감도
bool is_learning;
} motion_sample_t; // 샘플당 ~56 바이트10개를 하나의 MQTT publish로 묶으면 발행 횟수가 1/10로 줄고, 지연은 5초 이내로 유지된다.
구조체에 토크 예측 모델의 학습 파라미터가 들어 있다. 기기는 재귀 추정기로 위치·속도에서 예상 토크를 예측하는 theta[4] 계수를 갱신한다. p[4]는 추정기의 불확실성(공분산)이다. 초기에는 is_learning이 true이고 theta가 빠르게 변한다. 모델이 수렴하면 p가 0에 가까워지고 예측이 안정된다. 이 값을 실시간으로 올리기 때문에 Grafana Learning 패널에서 수렴 여부를 바로 확인할 수 있다 — theta가 계속 흔들리거나 p가 줄지 않으면 모델이 안정화되지 않은 것이므로 재캘리브레이션이 필요하다.
4) 클라우드 적재 (Lambda)
Lambda 함수는 프로토콜 버전 두 가지를 지원하고, 버전에 맞는 InfluxDB 버킷에 기록한다:
def lambda_handler(event, context):
message = event if isinstance(event, dict) else json.loads(event)
ver = message.get('ver', 1)
if ver >= 2:
lines, bucket = parse_protocol_v2(message)
else:
lines, bucket = parse_protocol_v1(message)
return write_to_influxdb(lines, bucket)각 파서는 JSON 샘플에 태그(serial_number, device_type)와 나노초 타임스탬프를 붙여 InfluxDB Line Protocol로 변환한다. v2에서는 하드웨어 버전 태그와 서보/센서 배열 펼치기가 추가됐다.
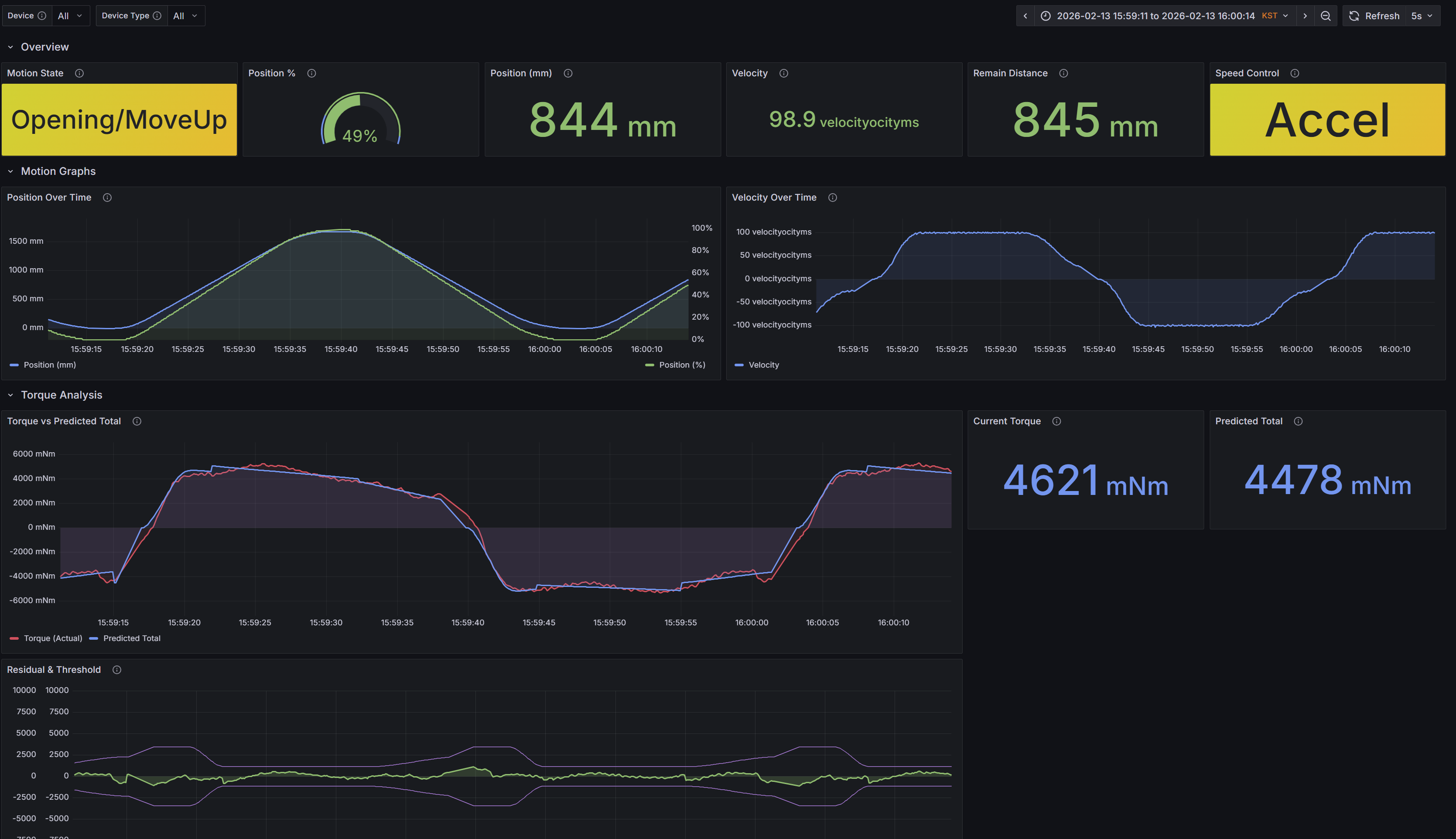
5) Grafana 대시보드
대시보드는 네 단계로 구성된다:
| 행 | 패널 | 용도 |
|---|---|---|
| Overview | 모션 상태, 위치 %, 위치 mm, 속도, 남은 거리, 속도 제어 | 기기 상태 한눈에 파악 |
| Motion Graphs | 시간별 위치, 시간별 속도 | 모션 프로파일 분석 |
| Torque Analysis | 실제 토크 vs 예측 토크 (경고/위험 임계값 포함), 현재 토크, 편차 | 이상 감지 |
| Learning | Theta, P 파라미터, 학습 상태 | 토크 모델 수렴 확인 |
토크 분석 패널에서 실제 토크와 예측값을 겹쳐 보여주고, 임계값(경고 15 Nm, 위험 20 Nm)을 함께 표시해서 기계적 이상을 바로 알아볼 수 있다.
트레이드오프
| 결정 | 근거 | 대가 |
|---|---|---|
| HTTP 대신 MQTT | 상시 연결, 작은 메시지를 자주 보내기에 오버헤드가 낮다 | ESP32에서 연결 관리를 직접 해야 한다 |
| DynamoDB 대신 InfluxDB | 시계열 쿼리에 특화, Grafana와 바로 연동 | EC2를 직접 운영해야 한다 |
| 수집에 Lambda 사용 | 트래픽에 따라 자동 확장, 서버 관리 불필요 | 콜드 스타트 지연이 있다 (모니터링 용도에는 문제없음) |
| 0.5초 모션 샘플링 | 토크 분석에 필요한 전체 모션 프로파일을 잡는다 | ~56 바이트 × 2/초 = 기기당 ~10 KB/분 |
| 배치 발행 (10개) | MQTT 발행 횟수를 1/10로 줄인다 | 데이터가 화면에 뜨기까지 최대 5초 걸린다 |
결과
원격 진단
- 고객 기기에서 가구-바닥 마찰을 원격으로 잡아냈다: 토크 분석 패널에서 특정 위치 구간마다 실제 토크가 예측보다 5 Nm 넘게 튀는 패턴이 보였고, 이동 경로상 가구 위치와 일치했다. 여러 사이클에서 같은 패턴이 반복돼 일시적 스파이크가 아닌 물리적 장애물로 확인
- 출장 없이 문제를 해결했다 — 이전에는 엔지니어가 직접 가야 했다
운영 현황
- 현재 10대 이상 기기를 운영 환경에서 모니터링 중, 배포 확대에 따라 증가
- 보존 기간이 다른(7일~1년) 4개 텔레메트리 채널 운용
시스템 성능
- 모션 텔레메트리: 기기당 2 샘플/초, 5초 배치 지연
- 기기 상태: CPU, 메모리, 서보, 센서 상태 상시 모니터링
- 토크 모델: 학습 파라미터를 실시간으로 확인하여 모델 수렴 여부 검증 가능
파이프라인 검증
- 기기 측
timestamp_ms와 InfluxDB 기록 시각을 비교해 종단 지연을 측정했다 — 샘플링부터 대시보드 표시까지 6초 이내 - 24시간 동안 기기 측 샘플 수와 InfluxDB 포인트 수를 대조해 데이터 무결성을 확인했다; 정상 연결 상태에서 유실 없음
핵심 교훈
가장 중요한 설계 선택은 텔레메트리를 단일 스트림으로 보내지 않고 데이터 특성별로 토픽을 나눈 것이다. 이렇게 하면 InfluxDB 보존 정책과 Grafana 쿼리 패턴에 그대로 대응되어, 고빈도 데이터는 짧게 보관해 비용을 줄이고 시스템 상태는 오래 보관해 추세를 볼 수 있다. 그중 가장 가치 있었던 기능은 실제 토크와 예측 토크를 실시간으로 비교하는 토크 모니터링이다. 직접 가서 확인해야 했을 기계적 문제를 원격으로 잡아낼 수 있게 됐다.